Visualization (t-SNE / UMAP)¶
GO3 can build gene-to-gene distance matrices from semantic similarity and use them for embedding.
Install extras¶
pip install go3[viz]
End-to-end example¶
import go3
go3.load_go_terms("go-basic.obo")
annots = go3.load_gaf("goa_human.gaf")
counter = go3.build_term_counter(annots)
genes = ["TP53", "BRCA1", "EGFR", "AKT1", "CASP8"]
# 1) Distance matrix from GO similarity
ordered_genes, dist = go3.gene_distance_matrix(
genes,
ontology="BP",
similarity="lin",
groupwise="bma",
counter=counter,
distance_transform="auto",
)
# 2) Embeddings (precomputed distance)
ordered_genes, emb_tsne = go3.tsne_genes(
genes,
"BP",
"lin",
"bma",
counter,
distance_transform="auto",
perplexity=2.0,
n_iter=500,
random_state=42,
)
ordered_genes, emb_umap = go3.umap_genes(
genes,
"BP",
"lin",
"bma",
counter,
distance_transform="auto",
n_neighbors=3,
min_dist=0.1,
random_state=42,
)
Plot helpers¶
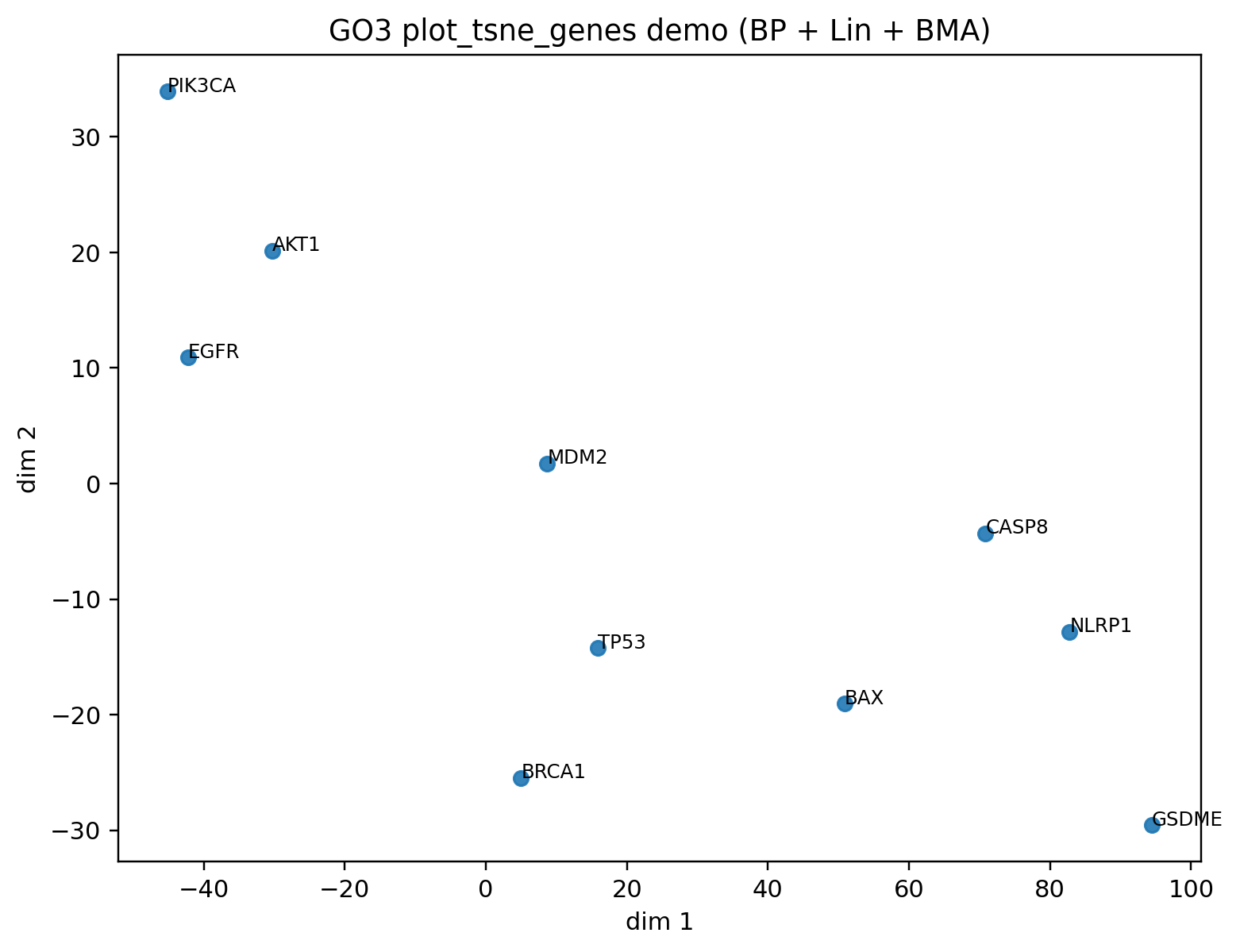
ordered_genes, emb, fig, ax = go3.plot_tsne_genes(
genes,
"BP",
"lin",
"bma",
counter,
perplexity=2.0,
n_iter=500,
random_state=42,
annotate="auto",
title="GO3 t-SNE",
)
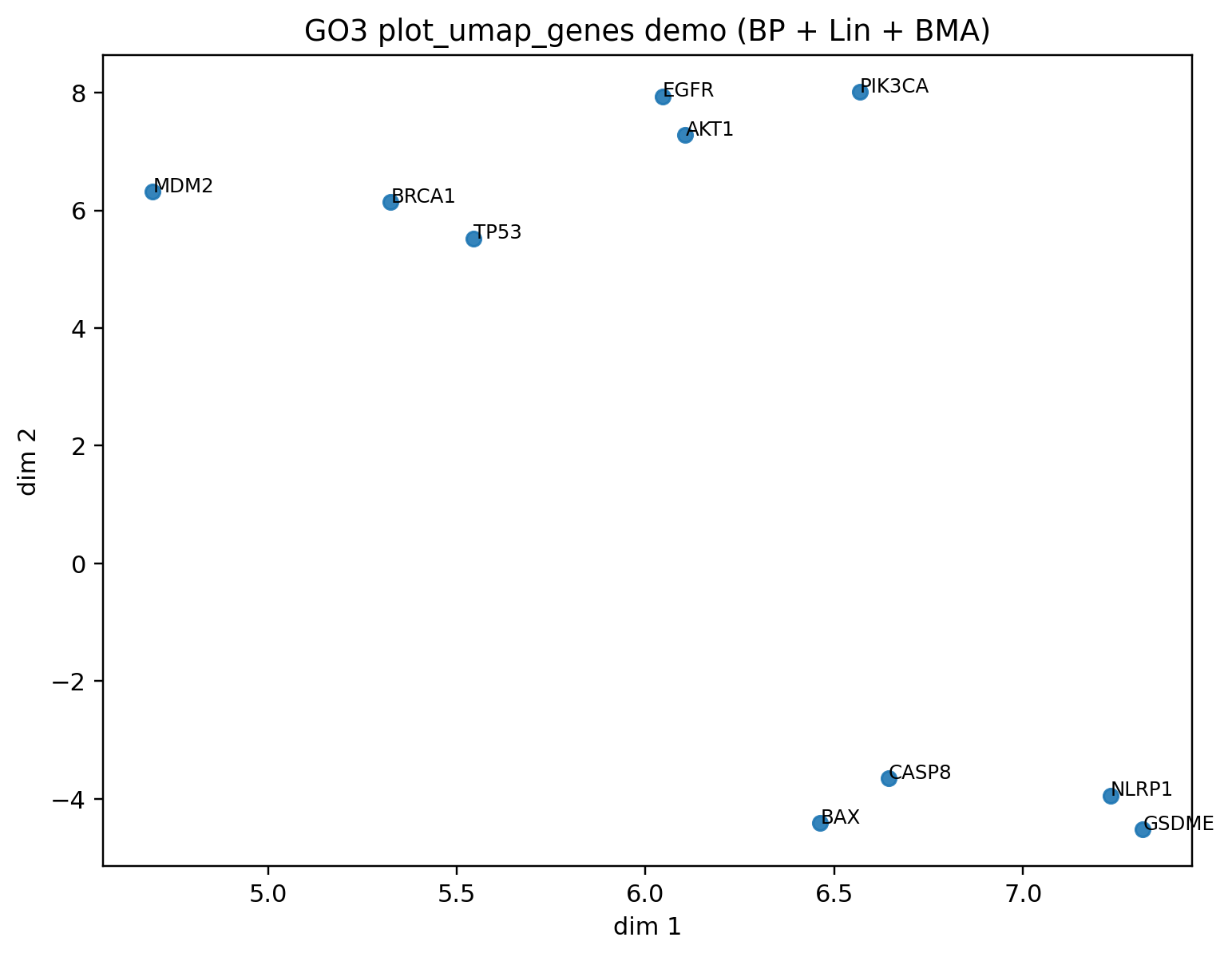
ordered_genes, emb_u, fig_u, ax_u = go3.plot_umap_genes(
genes,
"BP",
"lin",
"bma",
counter,
n_neighbors=3,
min_dist=0.1,
random_state=42,
annotate="auto",
title="GO3 UMAP",
)
Example output using plot helpers:
Understanding key parameters¶
Perplexity (t-SNE)¶
Perplexity roughly controls how many neighbors each point considers when computing the embedding. It balances attention between local and global structure:
Low perplexity (5–10): focuses on very local neighborhoods. Good for revealing tight clusters but may miss broader patterns.
High perplexity (30–50): considers more neighbors, capturing larger-scale structure but potentially merging distinct small clusters.
Rule of thumb: start with
perplexity ~ sqrt(n_genes). For 100 genes, try 10; for 1000 genes, try ~30.Hard constraint:
perplexitymust be strictly less than the number of genes.
n_neighbors (UMAP)¶
n_neighbors controls the size of the local neighborhood used to construct the UMAP graph:
Small n_neighbors (5–10): emphasizes fine-grained local structure. Good for finding small, tight clusters.
Large n_neighbors (30–50): captures more global topology. The embedding reflects broader relationships at the cost of local detail.
Rule of thumb: start with
n_neighbors ~ 15for exploratory analysis. Increase if the embedding looks too fragmented; decrease if clusters appear merged.Hard constraint:
n_neighborsmust be strictly less than the number of genes.
min_dist (UMAP)¶
min_dist controls how tightly points are allowed to pack together:
Small min_dist (0.0–0.1): allows dense clusters with clear separation.
Large min_dist (0.5–1.0): spreads points more evenly, which can improve readability for large datasets.
Distance transforms¶
gene_distance_matrix supports:
autoone_minusmax_minusreciprocal
auto is usually the best choice:
normalized similarities (
lin,wang,simrel,topoicsim) use a1 - simstyle transformnon-normalized similarities use a max-based transform
See the Utilities page for detailed descriptions of each transform.
Parameter constraints¶
tsne_genes:perplexity < number_of_genesumap_genes:n_neighbors < number_of_genesboth require at least 2 genes
Compare multiple settings¶
The repository includes a sweep demo script:
python scripts/embedding_sweep_demo.py --n-genes 80 --embed both
Custom sweep:
python scripts/embedding_sweep_demo.py \
--compare both \
--sweep-ontologies BP,MF,CC \
--sweep-similarities resnik,lin,wang,topoicsim \
--distance-transform auto \
--out-prefix embedding_sweep